Common issues when running Dapr
This guide covers common issues you may encounter while installing and running Dapr.
Dapr can’t connect to Docker when installing the Dapr CLI
When installing and initializing the Dapr CLI, if you see the following error message after running dapr init:
⌛ Making the jump to hyperspace...
❌ could not connect to docker. docker may not be installed or running
Troubleshoot the error by ensuring:
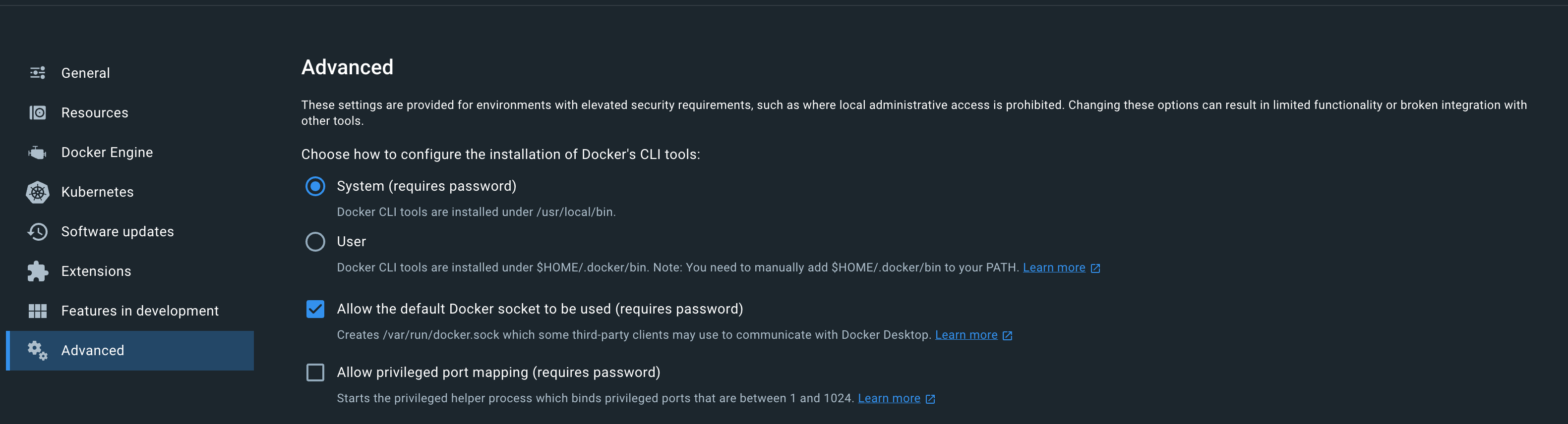
In Docker Desktop, verify the Allow the default Docker socket to be used (requires password) option is selected.
I don’t see the Dapr sidecar injected to my pod
There could be several reasons to why a sidecar will not be injected into a pod. First, check your deployment or pod YAML file, and check that you have the following annotations in the right place:
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "nodeapp"
dapr.io/app-port: "3000"
Sample deployment:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nodeapp
namespace: default
labels:
app: node
spec:
replicas: 1
selector:
matchLabels:
app: node
template:
metadata:
labels:
app: node
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "nodeapp"
dapr.io/app-port: "3000"
spec:
containers:
- name: node
image: dapriosamples/hello-k8s-node
ports:
- containerPort: 3000
imagePullPolicy: Always
There are some known cases where this might not properly work:
If your pod spec template is annotated correctly, and you still don’t see the sidecar injected, make sure Dapr was deployed to the cluster before your deployment or pod were deployed.
If this is the case, restarting the pods will fix the issue.
If you are deploying Dapr on a private GKE cluster, sidecar injection does not work without extra steps. See Setup a Google Kubernetes Engine cluster.
In order to further diagnose any issue, check the logs of the Dapr sidecar injector:
kubectl logs -l app=dapr-sidecar-injector -n dapr-systemNote: If you installed Dapr to a different namespace, replace dapr-system above with the desired namespace
If you are deploying Dapr on Amazon EKS and using an overlay network such as Calico, you will need to set
hostNetworkparameter to true, this is a limitation of EKS with such CNIs.You can set this parameter using Helm
values.yamlfile:helm upgrade --install dapr dapr/dapr \ --namespace dapr-system \ --create-namespace \ --values values.yamlvalues.yamldapr_sidecar_injector: hostNetwork: trueor using command line:
helm upgrade --install dapr dapr/dapr \ --namespace dapr-system \ --create-namespace \ --set dapr_sidecar_injector.hostNetwork=trueMake sure the kube api server can reach the following webhooks services:
- Sidecar Mutating Webhook Injector Service at port 4000 that is served from the sidecar injector.
- Resource Conversion Webhook Service at port 19443 that is served from the operator.
Check with your cluster administrators to setup allow ingress rules to the above ports, 4000 and 19443, in the cluster from the kube api servers.
My pod is in CrashLoopBackoff or another failed state due to the daprd sidecar
If the Dapr sidecar (daprd) is taking too long to initialize, this might be surfaced as a failing health check by Kubernetes.
If your pod is in a failed state you should check this:
kubectl describe pod <name-of-pod>
You might see a table like the following at the end of the command output:
Normal Created 7m41s (x2 over 8m2s) kubelet, aks-agentpool-12499885-vmss000000 Created container daprd
Normal Started 7m41s (x2 over 8m2s) kubelet, aks-agentpool-12499885-vmss000000 Started container daprd
Warning Unhealthy 7m28s (x5 over 7m58s) kubelet, aks-agentpool-12499885-vmss000000 Readiness probe failed: Get http://10.244.1.10:3500/v1.0/healthz: dial tcp 10.244.1.10:3500: connect: connection refused
Warning Unhealthy 7m25s (x6 over 7m55s) kubelet, aks-agentpool-12499885-vmss000000 Liveness probe failed: Get http://10.244.1.10:3500/v1.0/healthz: dial tcp 10.244.1.10:3500: connect: connection refused
Normal Killing 7m25s (x2 over 7m43s) kubelet, aks-agentpool-12499885-vmss000000 Container daprd failed liveness probe, will be restarted
Warning BackOff 3m2s (x18 over 6m48s) kubelet, aks-agentpool-12499885-vmss000000 Back-off restarting failed container
The message Container daprd failed liveness probe, will be restarted indicates at the Dapr sidecar has failed its health checks and will be restarted. The messages Readiness probe failed: Get http://10.244.1.10:3500/v1.0/healthz: dial tcp 10.244.1.10:3500: connect: connection refused and Liveness probe failed: Get http://10.244.1.10:3500/v1.0/healthz: dial tcp 10.244.1.10:3500: connect: connection refused show that the health check failed because no connection could be made to the sidecar.
The most common cause of this failure is that a component (such as a state store) is misconfigured and is causing initialization to take too long. When initialization takes a long time, it’s possible that the health check could terminate the sidecar before anything useful is logged by the sidecar.
To diagnose the root cause:
- Significantly increase the liveness probe delay - link
- Set the log level of the sidecar to debug - link
- Watch the logs for meaningful information - link
Remember to configure the liveness check delay and log level back to your desired values after solving the problem.
I am unable to save state or get state
Have you installed an Dapr State store in your cluster?
To check, use kubectl get a list of components:
kubectl get components
If there isn’t a state store component, it means you need to set one up. Visit here for more details.
If everything’s set up correctly, make sure you got the credentials right. Search the Dapr runtime logs and look for any state store errors:
kubectl logs <name-of-pod> daprd
I am unable to publish and receive events
Have you installed an Dapr Message Bus in your cluster?
To check, use kubectl get a list of components:
kubectl get components
If there isn’t a pub/sub component, it means you need to set one up. Visit here for more details.
If everything is set up correctly, make sure you got the credentials right. Search the Dapr runtime logs and look for any pub/sub errors:
kubectl logs <name-of-pod> daprd
I’m getting 500 Error responses when calling Dapr
This means there are some internal issue inside the Dapr runtime. To diagnose, view the logs of the sidecar:
kubectl logs <name-of-pod> daprd
I’m getting 404 Not Found responses when calling Dapr
This means you’re trying to call an Dapr API endpoint that either doesn’t exist or the URL is malformed. Look at the Dapr API reference here and make sure you’re calling the right endpoint.
I don’t see any incoming events or calls from other services
Have you specified the port your app is listening on?
In Kubernetes, make sure the dapr.io/app-port annotation is specified:
annotations:
dapr.io/enabled: "true"
dapr.io/app-id: "nodeapp"
dapr.io/app-port: "3000"
If using Dapr Standalone and the Dapr CLI, make sure you pass the --app-port flag to the dapr run command.
My Dapr-enabled app isn’t behaving correctly
The first thing to do is inspect the HTTP error code returned from the Dapr API, if any.
If you still can’t find the issue, try enabling debug log levels for the Dapr runtime. See here how to do so.
You might also want to look at error logs from your own process. If running on Kubernetes, find the pod containing your app, and execute the following:
kubectl logs <pod-name> <name-of-your-container>
If running in Standalone mode, you should see the stderr and stdout outputs from your app displayed in the main console session.
I’m getting timeout/connection errors when running Actors locally
Each Dapr instance reports it’s host address to the placement service. The placement service then distributes a table of nodes and their addresses to all Dapr instances. If that host address is unreachable, you are likely to encounter socket timeout errors or other variants of failing request errors.
Unless the host name has been specified by setting an environment variable named DAPR_HOST_IP to a reachable, pingable address, Dapr will loop over the network interfaces and select the first non-loopback address it finds.
As described above, in order to tell Dapr what the host name should be used, simply set an environment variable with the name of DAPR_HOST_IP.
The following example shows how to set the Host IP env var to 127.0.0.1:
Note: for versions <= 0.4.0 use HOST_IP
export DAPR_HOST_IP=127.0.0.1
None of my components are getting loaded when my application starts. I keep getting “Error component X cannot be found”
This is usually due to one of the following issues
- You may have defined the
NAMESPACEenvironment variable locally or deployed your components into a different namespace in Kubernetes. Check which namespace your app and the components are deployed to. Read scoping components to one or more applications for more information. - You may have not provided a
--resources-pathwith the Daprruncommands or not placed your components into the default components folder for your OS. Read define a component for more information. - You may have a syntax issue in component YAML file. Check your component YAML with the component YAML samples.
Service invocation is failing and my Dapr service is missing an appId (macOS)
Some organizations will implement software that filters out all UDP traffic, which is what mDNS is based on. Mostly commonly, on MacOS, Microsoft Content Filter is the culprit.
In order for mDNS to function properly, ensure Microsoft Content Filter is inactive.
- Open a terminal shell.
- Type
mdatp system-extension network-filter disableand hit enter. - Enter your account password.
Microsoft Content Filter is disabled when the output is “Success”.
Some organizations will re-enable the filter from time to time. If you repeatedly encounter app-id values missing, first check to see if the filter has been re-enabled before doing more extensive troubleshooting.
Admission webhook denied the request
You may encounter an error similar to the one below because the sidecar injector’s admission webhook only processes requests from authorized service accounts. The service account that created the pod is not in the injector’s allowlist.
root:[dapr]$ kubectl run -i --tty --rm debug --image=busybox --restart=Never -- sh
Error from server: admission webhook "sidecar-injector.dapr.io" denied the request: service account 'user-xdd5l' not on the list of allowed controller accounts
To resolve this error, either:
Add the service account to the injector’s authorized list by configuring the
dapr_sidecar_injector.allowedServiceAccountsHelm value. Glob patterns are supported (for example,my-namespace:*to authorize all service accounts in a namespace). See the Sidecar Injector documentation for details.Or, create a
clusterrolebindingfor the current user:kubectl create clusterrolebinding dapr-<name-of-user> --clusterrole=dapr-operator-admin --user <name-of-user>You can run the below command to get all users in your cluster:
kubectl config get-users
You may learn more about webhooks here.
Ports not available during dapr init
You might encounter the following error on Windows after attempting to execute dapr init:
PS C:\Users\You> dapr init Making the jump to hyperspace… Container images will be pulled from Docker Hub Installing runtime version 1.14.4 Downloading binaries and setting up components… docker: Error response from daemon: Ports are not available: exposing port TCP 0.0.0.0:52379 -> 0.0.0.0:0: listen tcp4 0.0.0.0:52379: bind: An attempt was made to access a socket in a way forbidden by its access permissions.
To resolve this error, open a command prompt in an elevated terminal and run:
net stop winnat
dapr init
net start winnat