工作流架构
Dapr 工作流允许开发者使用多种编程语言的普通代码来定义工作流。工作流引擎运行在 Dapr 边车内部,协调作为应用程序一部分部署的工作流代码。Dapr 工作流构建在 Dapr Actor 之上,为工作流执行提供持久性和可扩展性。
本文介绍:
- Dapr 工作流引擎的架构
- 工作流引擎如何与应用程序代码交互
- 工作流引擎如何融入整体 Dapr 架构
- 不同的工作流后端如何与工作流引擎配合使用
有关如何在应用程序中编写 Dapr 工作流的更多信息,请参阅如何:编写工作流。
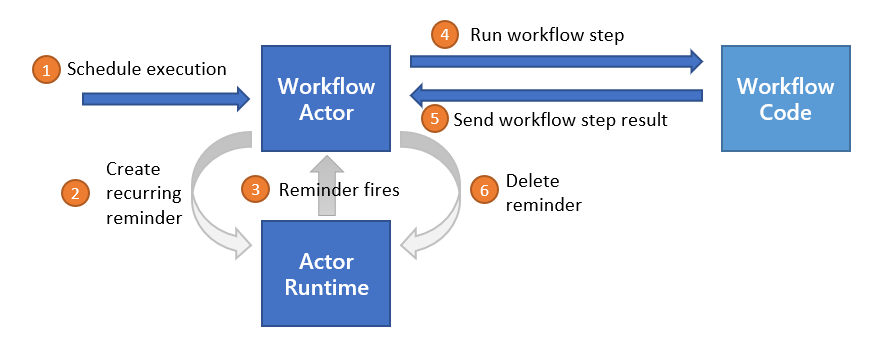
Dapr 工作流引擎内部由 Dapr 的 actor 运行时驱动。下图展示了 Kubernetes 模式下的 Dapr 工作流架构:
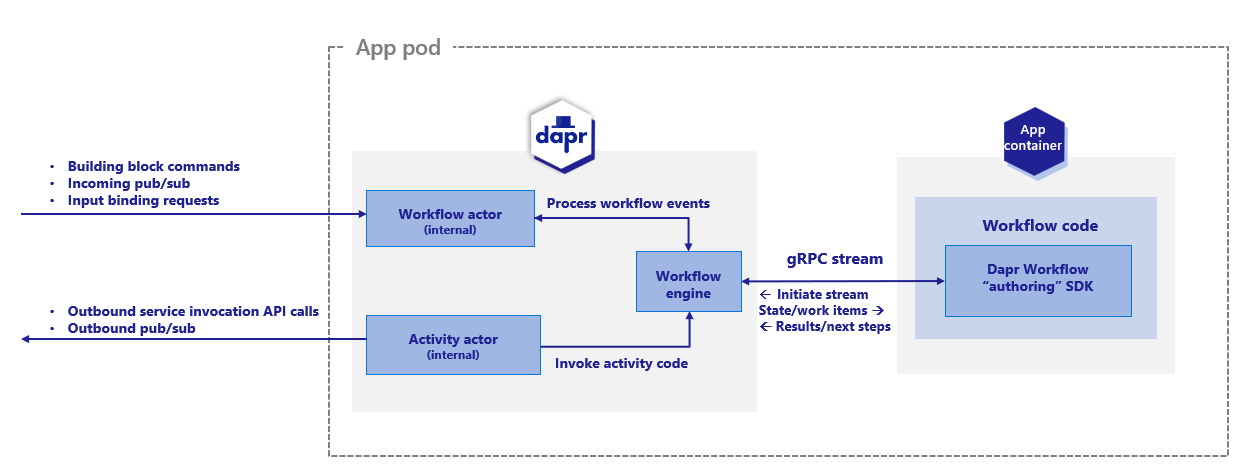
要使用 Dapr 工作流构建块,您需要使用 Dapr Workflow SDK 在应用程序中编写工作流代码,SDK 内部使用 gRPC 流连接到边车。这会注册工作流以及任何工作流活动,或工作流可以调度的任务。
引擎直接嵌入到边车中,并使用 durabletask-go 框架库实现。该框架允许您交换不同的存储提供程序,包括为 Dapr 创建的存储提供程序,它在幕后利用内部 actor。由于 Dapr 工作流使用 actor,您可以将工作流状态存储在状态存储中。
边车交互
当工作流应用程序启动时,它使用工作流编写 SDK 向 Dapr 边车发送 gRPC 请求,并获取工作流工作项的流,遵循服务器流式 RPC 模式。这些工作项可以是任何内容,从"启动新的 X 工作流"(其中 X 是工作流的类型)到"代表工作流 X 调度具有输入 Z 的活动 Y"。
工作流应用程序执行适当的工作流代码,然后向边车发送 gRPC 请求,其中包含执行结果。
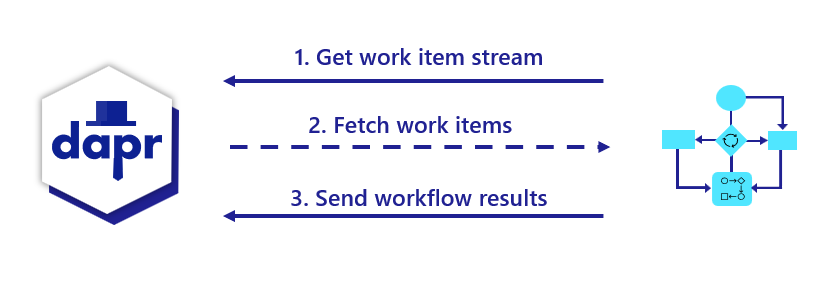
所有交互都通过单个 gRPC 通道进行,并由应用程序发起,这意味着应用程序不需要打开任何入站端口。 这些交互的细节由特定语言的 Dapr 工作流编写 SDK 内部处理。
工作流与应用程序 actor 交互的区别
如果您熟悉 Dapr actor,您可能会注意到,与应用程序定义的 actor 相比,工作流的边车交互方式有一些差异。
| Actor | 工作流 |
|---|---|
| 应用程序创建的 actor 可以使用 HTTP 或 gRPC 与边车交互。 | 工作流仅使用 gRPC。由于工作流 gRPC 协议的复杂性,实现工作流时_必须_使用 SDK。 |
| Actor 操作从边车推送到应用程序代码。这要求应用程序监听特定的_应用端口_。 | 对于工作流,操作由应用程序使用流式协议从边车_拉取_。应用程序不需要监听任何端口即可运行工作流。 |
| Actor 向边车显式注册自己。 | 工作流不向边车注册自己。嵌入式引擎不跟踪工作流类型。此职责委托给工作流应用程序及其 SDK。 |
工作流分布式跟踪
工作流引擎使用的 durabletask-go 核心使用 Open Telemetry SDK 编写分布式跟踪。
这些跟踪由 Dapr 边车自动捕获,并导出到配置的 Open Telemetry 提供程序,例如 Zipkin。
引擎管理的每个工作流实例表示为一个或多个 span。 有一个表示完整工作流执行的父 span,以及各种任务的子 span,包括活动任务执行和持久化计时器的 span。
工作流活动代码当前_不能_访问跟踪上下文。
工作流 actor
当工作流客户端连接到边车时,会注册两种类型的 actor 以支持工作流引擎:
dapr.internal.{namespace}.{appID}.workflowdapr.internal.{namespace}.{appID}.activity
{namespace} 值是 Dapr 命名空间,如果未配置命名空间,则默认为 default。
{appID} 值是应用程序的 ID。
例如,如果您有一个名为"wfapp"的工作流应用程序,则工作流 actor 的类型为 dapr.internal.default.wfapp.workflow,活动 actor 的类型为 dapr.internal.default.wfapp.activity。
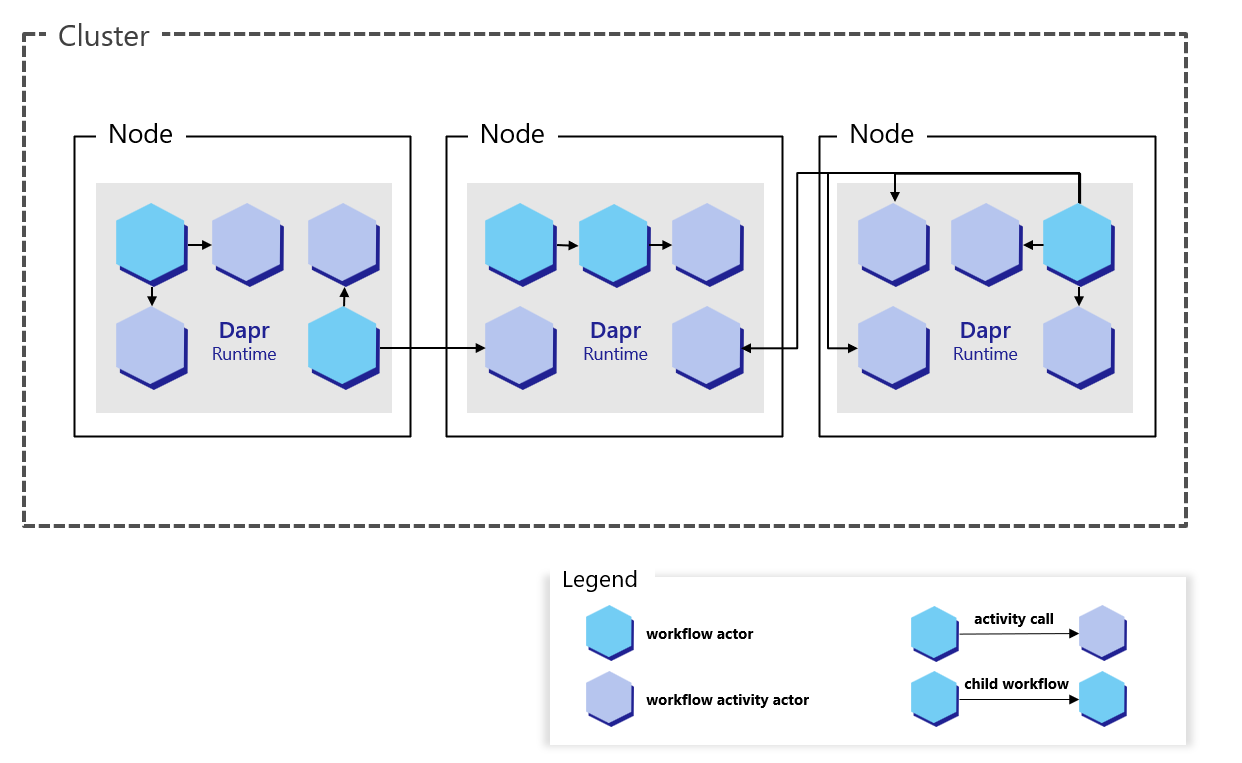
下图演示了工作流 actor 在 Kubernetes 场景中如何运行:
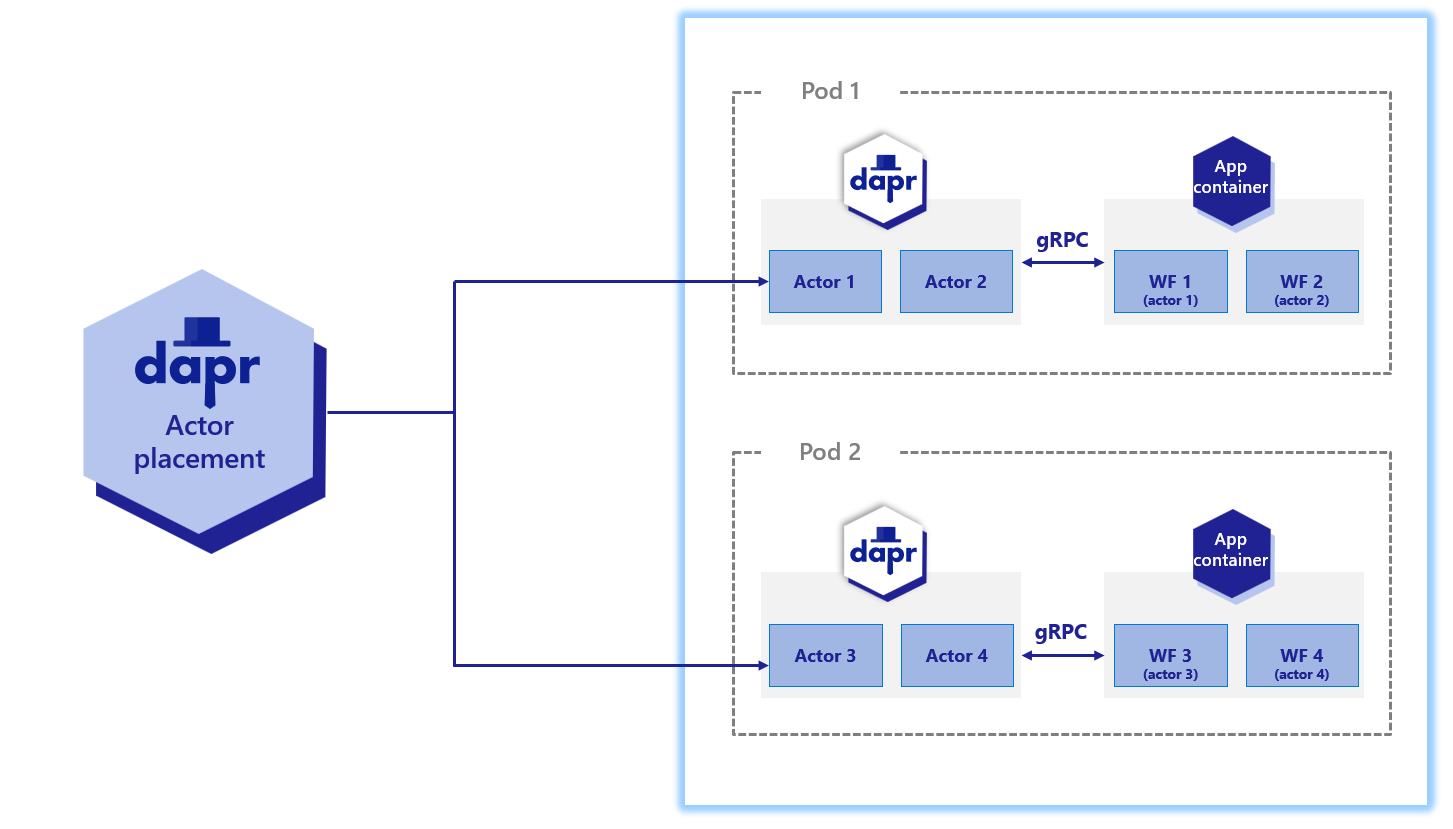
与用户定义的 actor 一样,工作流 actor 通过 actor 放置服务提供的哈希查找表分布在集群中。 它们还维护自己的状态并使用提醒。 但是,与应用程序代码中的 actor 不同,这些工作流 actor 嵌入到 Dapr 边车中。 应用程序代码完全不知道这些 actor 的存在。
注意
工作流 actor 类型仅在应用程序使用 Dapr Workflow SDK 注册工作流后才注册。 如果应用程序从未注册工作流,则永远不会注册内部工作流 actor。
工作流 actor
工作流使用两种不同类型的 actor:工作流 actor 和活动 actor。 工作流 actor 负责管理应用程序中运行的所有工作流的状态和位置。 为每个被调度的工作流实例激活一个新的工作流 actor 实例。 工作流 actor 的 ID 是工作流的 ID。 此工作流 actor 在工作流进行时存储工作流的状态,并通过 actor 查找表确定工作流代码在哪个节点上执行。
由于工作流基于 actor,所有工作流和活动工作在实现工作流的应用程序的所有副本之间随机分布。 工作流启动的位置与每个工作项执行的位置之间没有局部性或关系。
每个工作流 actor 使用配置的 actor 状态存储中的以下键保存其状态:
| 键 | 描述 |
|---|---|
inbox-NNNNNN | 工作流的收件箱实际上是驱动工作流执行的_消息_的 FIFO 队列。示例消息包括工作流创建消息、活动任务完成消息等。每条消息作为单独的键存储在状态存储中,名称为 inbox-NNNNNN,其中 NNNNNN 是一个 6 位数字,表示消息的顺序。一旦工作流消耗了相应的消息,这些状态键就会被删除。 |
history-NNNNNN | 工作流的历史是表示工作流执行历史的事件的有序列表。历史中的每个键保存单个历史事件的数据。像仅追加日志一样,工作流历史事件只添加,从不删除(除非工作流执行"继续作为新"操作,这会清除所有历史记录并使用新输入重新启动工作流)。 |
customStatus | 包含用户定义的工作流状态值。每个工作流 actor 实例恰好有一个 customStatus 键。 |
metadata | 包含有关工作流的元信息,作为 JSON blob,包括收件箱长度、历史记录长度以及表示工作流生成的 64 位整数(用于实例 ID 被重用的情况)。长度信息用于确定在加载或保存工作流状态更新时需要读取或写入哪些键。 |
警告
工作流 actor 状态在工作流完成后仍保留在状态存储中。
创建大量工作流可能导致无限制的存储使用。 要解决此问题,可以使用工作流的 ID 清除工作流或直接删除工作流数据库存储中的条目。
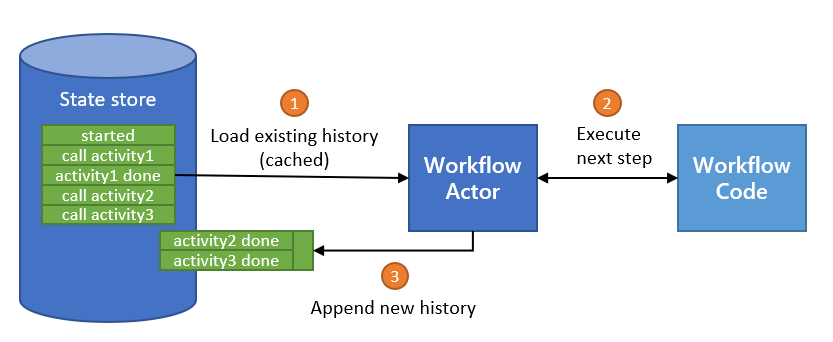
下图说明了工作流 actor 的典型生命周期。
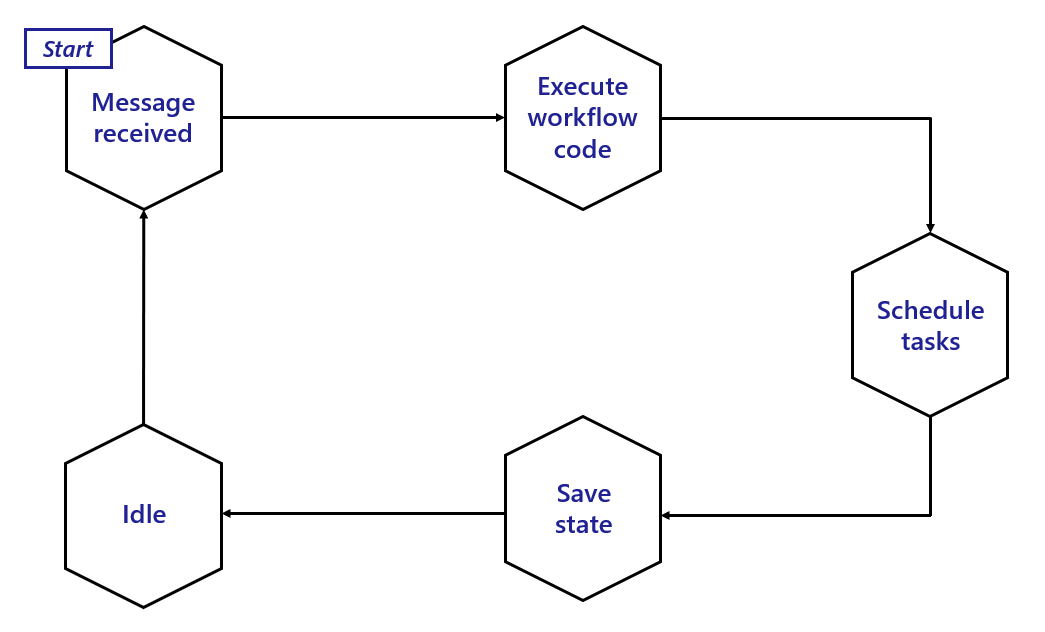
总结:
- 工作流 actor 在收到新消息时被激活。
- 新消息随后触发相关的工作流代码(在您的应用程序中)运行,并将执行结果返回给工作流 actor。
- 收到结果后,actor 根据需要调度任何任务。
- 调度后,actor 更新其在状态存储中的状态。
- 最后,actor 进入空闲状态,直到收到另一条消息。在此空闲期间,边车可能决定从内存中卸载工作流 actor。
活动 actor
活动 actor 负责管理所有工作流活动调用的状态和位置。
为工作流调度的每个活动任务激活一个新的活动 actor 实例。
活动 actor 的 ID 是工作流的 ID 加上序列号(序列号从 0 开始)以及"生成"(在使用 continue as new 重新运行的实例期间递增)的组合。
例如,如果工作流的 ID 为 876bf371,并且是工作流调度的第三个活动,其 ID 将为 876bf371::2::1,其中 2 是序列号,1 是生成。
如果活动在 continue as new 后再次被调度,ID 将为 876bf371::2::2。
活动 actor 不存储任何状态,而是将所有结果数据发送回父工作流 actor。
下图说明了活动 actor 的典型生命周期。
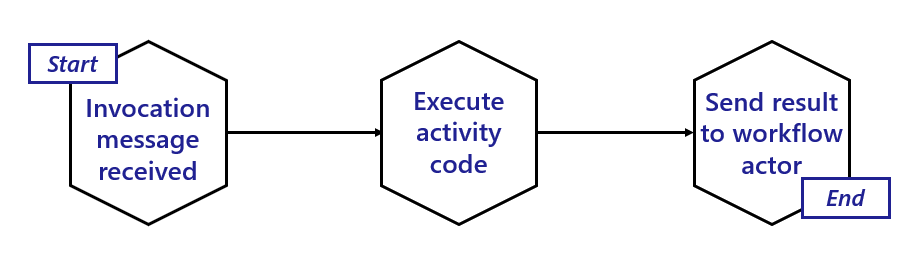
活动 actor 是短寿命的:
- 当工作流 actor 调度活动任务时,活动 actor 被激活。
- 活动 actor 立即调用工作流应用程序以调用相关的活动代码。
- 活动代码运行完成并返回其结果后,活动 actor 向父工作流 actor 发送带有执行结果的消息。
- 活动 actor 然后停用自己。
- 发送结果后,工作流被触发继续进行下一步。
提醒使用和执行保证
Dapr 工作流通过使用 actor 提醒来确保工作流容错性,以从瞬态系统故障中恢复。 在调用应用程序工作流代码之前,工作流或活动 actor 将创建一个新的提醒。 这些提醒是"一次性"的,意味着它们将在成功触发后过期。 如果应用程序代码无中断地执行,提醒将被触发并过期。 但是,如果托管相关工作流或活动的节点或边车崩溃,提醒将重新激活相应的 actor,并且将永远重试执行。
状态存储使用
Dapr 工作流内部使用 actor 来驱动工作流的执行。
与任何 actor 一样,这些工作流 actor 将其状态存储在配置的 actor 状态存储中。
这是通过在 Dapr 配置中指定状态存储组件,然后在配置的 actors 部分的 actorStateStore 属性中引用该状态存储来完成的。
阅读状态 API 参考和 actor API 参考以了解更多关于 actor 状态存储的信息。
如工作流 actor部分所述,工作流通过附加到历史日志来增量保存其状态。 工作流的历史日志分布在多个状态存储键中,以便每个"检查点"仅需要附加最新的条目。
每个检查点的大小由工作流在进入空闲状态之前调度的并发操作数确定。 顺序工作流因此会对状态存储进行较小的批量更新,而扇出/扇入工作流将需要更大的批量。 批量大小也受工作流调用活动或子工作流时输入和输出大小的影响。
不同的状态存储实现可能会隐式地限制您可以编写的工作流类型。 例如,Azure Cosmos DB 状态存储将项目大小限制为 2 MB 的 UTF-8 编码 JSON(来源)。 活动或子工作流的输入或输出负载作为单个记录存储在状态存储中,因此 2 MB 的项目限制意味着工作流和活动的输入和输出不能超过 2 MB 的 JSON 序列化数据。
同样,如果状态存储对批量事务的大小施加限制,这可能会限制工作流可以调度的并行操作数量。
可以从状态存储中清除工作流状态,包括其所有历史记录。 每个 Dapr SDK 都公开了用于清除特定工作流实例的所有元数据的 API。
状态存储记录数
每次工作流运行在状态存储中保存为历史记录的记录数由其复杂性或"形状"决定。换句话说,即活动、计时器、子工作流等的数量。 下表显示了不同工作流任务保存的记录数的一般指南。 根据重试或并发性,此数字可能更大或更小。
| 任务类型 | 保存的记录数 |
|---|---|
| 启动工作流 | 5 条记录 |
| 调用活动 | 3 条记录 |
| 计时器 | 3 条记录 |
| 触发事件 | 3 条记录 |
| 启动子工作流 | 8 条记录 |
查询工作流历史
dapr workflow --app-id myapp list
dapr workflow --app-id myapp history <instance-id>
支持的状态存储
工作流引擎支持以下状态存储:
- PostgreSQL
- MySQL
- SQL Server
- SQLite
- Oracle Database
- CockroachDB
- MongoDB
- Redis
工作流可扩展性
由于 Dapr 工作流内部使用 actor 实现,Dapr 工作流具有与 actor 相同的可扩展性特征。 放置服务:
- 不区分工作流 actor 和您在应用程序中定义的 actor
- 将使用与 actor 相同的算法对工作流进行负载平衡
工作流的预期可扩展性由以下因素决定:
- 用于托管工作流应用程序的计算机数量
- 运行工作流的计算机上可用的 CPU 和内存资源
- 为 actor 配置的状态存储的可扩展性
- actor 放置服务和提醒子系统的可扩展性
目标应用程序中工作流代码的实现细节也在单个工作流实例的可扩展性中发挥作用。 每个工作流实例一次在单个节点上执行,但工作流可以调度在其他节点上运行的活动和子工作流。
工作流还可以调度这些活动和子工作流并行运行,允许单个工作流可能在整个集群的所有可用节点上分布计算任务。
您可以使用 Dapr 配置配置工作流和活动的最大并发性,如下一节所述。
重要
默认情况下,工作流和活动并发性没有施加全局限制。 因此,如果失控工作流尝试并行调度太多任务,可能会消耗集群中的所有资源。 在编写并行调度大批量工作的 Dapr 工作流时,请小心。重要
Dapr 工作流引擎要求工作流应用程序的所有实例注册完全相同的一组工作流和活动。 换句话说,不可能独立扩展某些工作流或活动。 应用程序中的所有工作流和活动必须一起扩展。工作流不控制负载如何在集群中分布的细节。 例如,如果工作流调度 10 个活动任务并行运行,所有 10 个任务可能运行在多达 10 个不同的计算节点上,也可能运行在单个计算节点上。 实际扩展行为由 actor 放置服务决定,该服务管理表示工作流每个任务的 actor 的分布。
工作流延迟
为了提供持久性和弹性保证,Dapr 工作流频繁写入状态存储并依赖提醒来驱动执行。 因此,Dapr 工作流可能不适合延迟敏感的工作负载。 高延迟的预期来源包括:
- 持久化工作流状态时状态存储的延迟。
- 使用大型历史记录重新水合工作流时状态存储的延迟。
- 集群中太多活动提醒引起的延迟。
- 集群中高 CPU 使用率引起的延迟。
有关工作流 actor 的设计如何影响执行延迟的更多详细信息,请参阅提醒使用和执行保证部分。
提高调度吞吐量
默认情况下,当客户端调度工作流时,工作流引擎会等待工作流完全启动后再向客户端返回响应。 在返回之前等待工作流启动会降低工作流的调度吞吐量。 当调度具有开始时间的工作流时,工作流引擎不会等待工作流启动就向客户端返回响应。 要提高调度吞吐量,请考虑在调度工作流时添加"现在"的开始时间。 以下显示了在 Go SDK 中调度开始时间为"现在"的工作流的示例:
client.ScheduleNewWorkflow(ctx, "MyCoolWorkflow", workflow.WithStartTime(time.Now()))
使用 Dapr Shared 与工作流时的工作流集群部署
注意
以下功能仅在启用工作流集群部署预览功能时可用。当使用 Dapr Shared时,可能会有多个 daprd 边车在单个负载均衡器或服务后面运行。
因此,接收工作的辅助实例可能不是接收工作结果的实例。
Dapr 创建第三种 actor 类型来处理此场景:dapr.internal.{namespace}.{appID}.executor,用于将辅助结果路由回正确的工作流 actor,以确保正确操作。