操作指南:在 Kubernetes 中设置 Fluentd、Elasticsearch 和 Kibana
前置条件
安装 Elasticsearch 和 Kibana
为监控工具创建一个 Kubernetes 命名空间
kubectl create namespace dapr-monitoring添加 Elasticsearch 的 helm 仓库
helm repo add elastic https://helm.elastic.co helm repo update使用 Helm 安装 Elasticsearch
默认情况下,该 chart 会创建 3 个副本,这些副本必须分布在不同的节点上。如果你的集群节点数少于 3 个,请指定较小的副本数。例如,以下命令将副本数设置为 1:
helm install elasticsearch elastic/elasticsearch --version 7.17.3 -n dapr-monitoring --set replicas=1否则:
helm install elasticsearch elastic/elasticsearch --version 7.17.3 -n dapr-monitoring如果你正在使用 minikube 或只是为了开发目的想禁用持久卷,可以使用以下命令:
helm install elasticsearch elastic/elasticsearch --version 7.17.3 -n dapr-monitoring --set persistence.enabled=false,replicas=1安装 Kibana
helm install kibana elastic/kibana --version 7.17.3 -n dapr-monitoring确保 Elasticsearch 和 Kibana 在你的 Kubernetes 集群中运行
$ kubectl get pods -n dapr-monitoring NAME READY STATUS RESTARTS AGE elasticsearch-master-0 1/1 Running 0 6m58s kibana-kibana-95bc54b89-zqdrk 1/1 Running 0 4m21s
安装 Fluentd
安装 config map 和以 daemonset 方式运行的 Fluentd
下载这些配置文件:
注意:如果你的集群中已经有 Fluentd 在运行,请启用嵌套 JSON 解析器,以便它可以解析来自 Dapr 的 JSON 格式日志。
将配置应用到你的集群:
kubectl apply -f ./fluentd-config-map.yaml kubectl apply -f ./fluentd-dapr-with-rbac.yaml确保 Fluentd 作为 daemonset 运行。Fluentd 实例的数量应与集群节点数相同。在下面的示例中,集群中只有一个节点:
$ kubectl get pods -n kube-system -w NAME READY STATUS RESTARTS AGE coredns-6955765f44-cxjxk 1/1 Running 0 4m41s coredns-6955765f44-jlskv 1/1 Running 0 4m41s etcd-m01 1/1 Running 0 4m48s fluentd-sdrld 1/1 Running 0 14s
安装支持 JSON 格式日志的 Dapr
安装 Dapr 并启用 JSON 格式日志
helm repo add dapr https://dapr.github.io/helm-charts/ helm repo update helm install dapr dapr/dapr --namespace dapr-system --set global.logAsJson=true在 Dapr sidecar 中启用 JSON 格式日志
将
dapr.io/log-as-json: "true"注解添加到你的 deployment yaml 中。例如:apiVersion: apps/v1 kind: Deployment metadata: name: pythonapp namespace: default labels: app: python spec: replicas: 1 selector: matchLabels: app: python template: metadata: labels: app: python annotations: dapr.io/enabled: "true" dapr.io/app-id: "pythonapp" dapr.io/log-as-json: "true" ...
搜索日志
注意:Elasticsearch 需要一些时间来索引 Fluentd 发送的日志。
从本地端口转发到
svc/kibana-kibana$ kubectl port-forward svc/kibana-kibana 5601 -n dapr-monitoring Forwarding from 127.0.0.1:5601 -> 5601 Forwarding from [::1]:5601 -> 5601 Handling connection for 5601 Handling connection for 5601浏览到
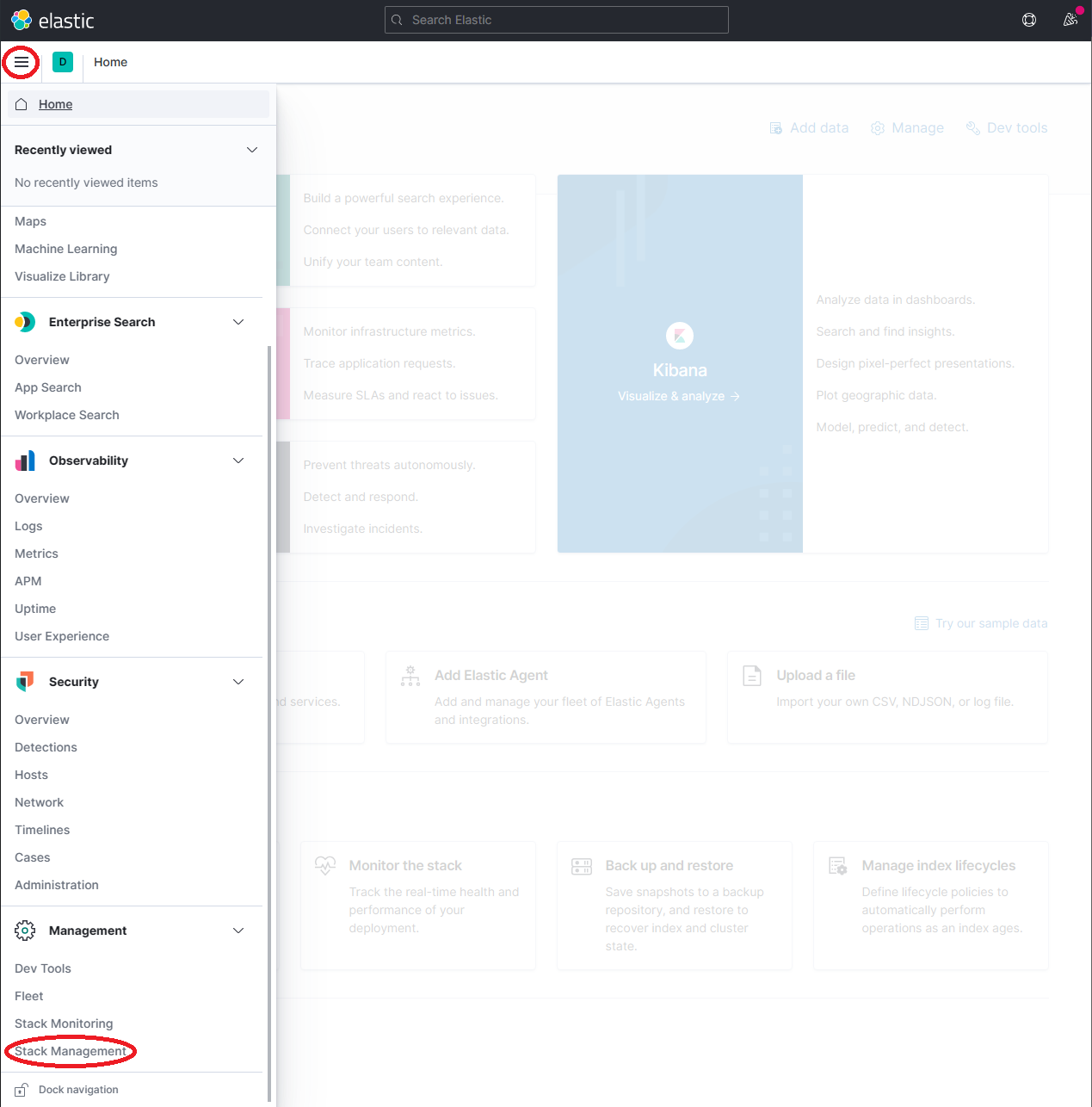
http://localhost:5601展开下拉菜单并点击 Management → Stack Management
在 Stack Management 页面上,选择 Data → Index Management 并等待
dapr-*被索引。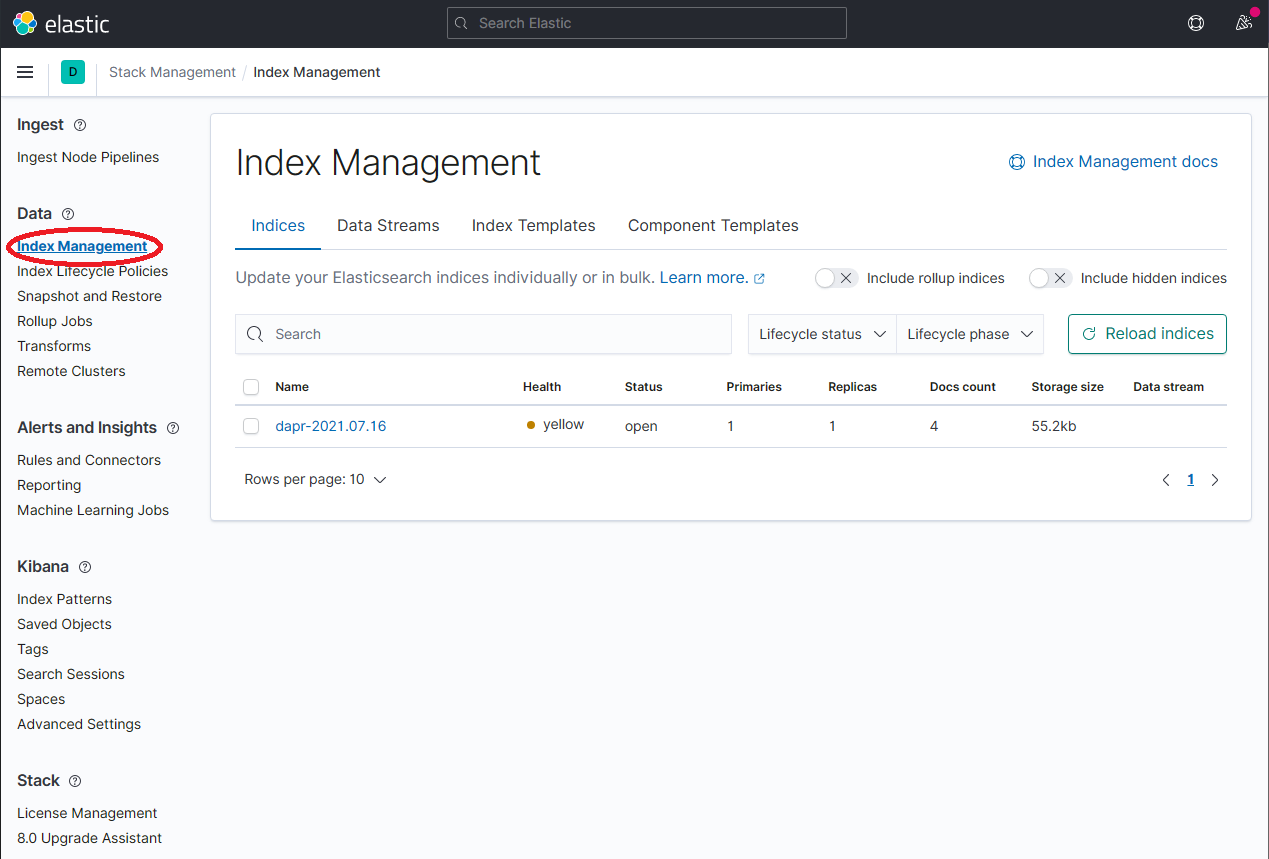
一旦
dapr-*被索引,点击 Kibana → Index Patterns,然后点击 Create index pattern 按钮。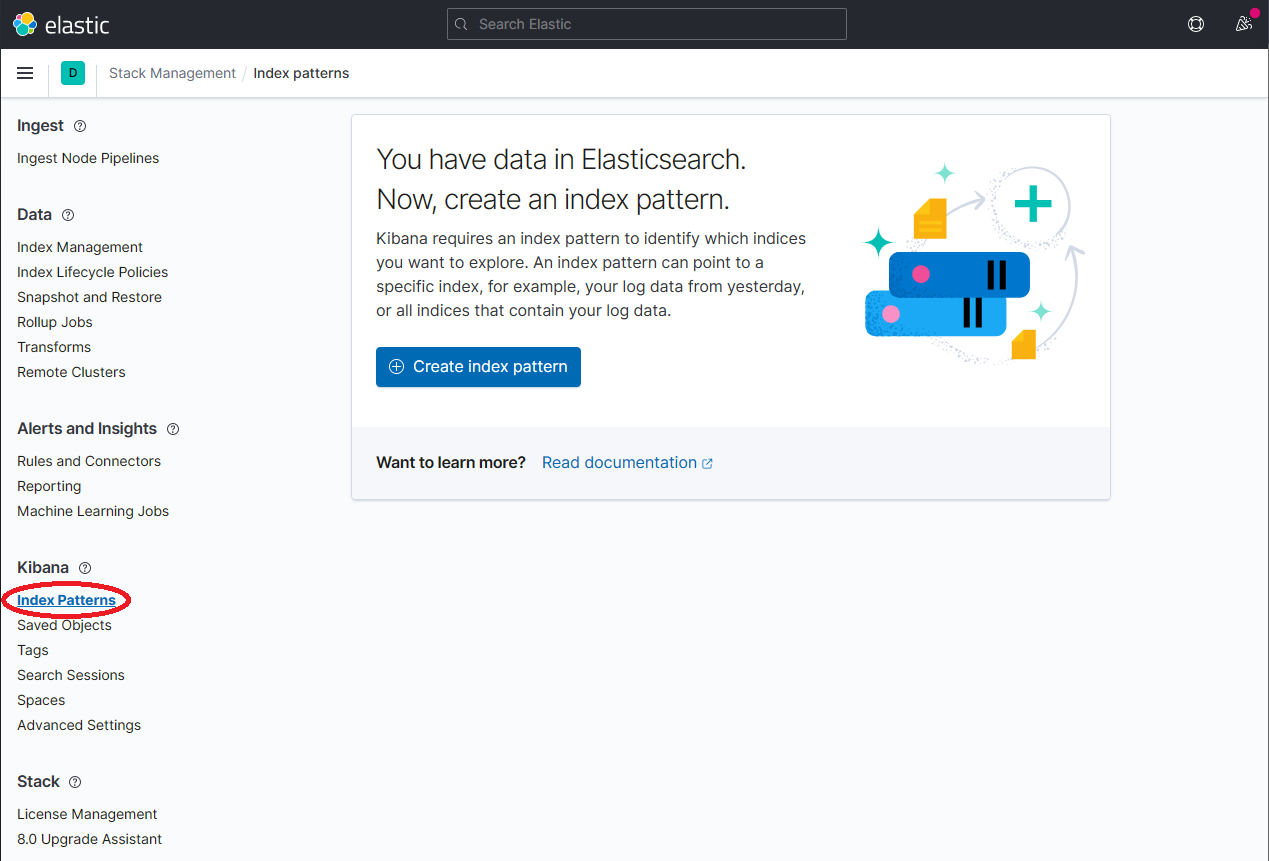
通过在 Index Pattern name 字段中输入
dapr*来定义新的索引模式,然后点击 Next step 按钮继续。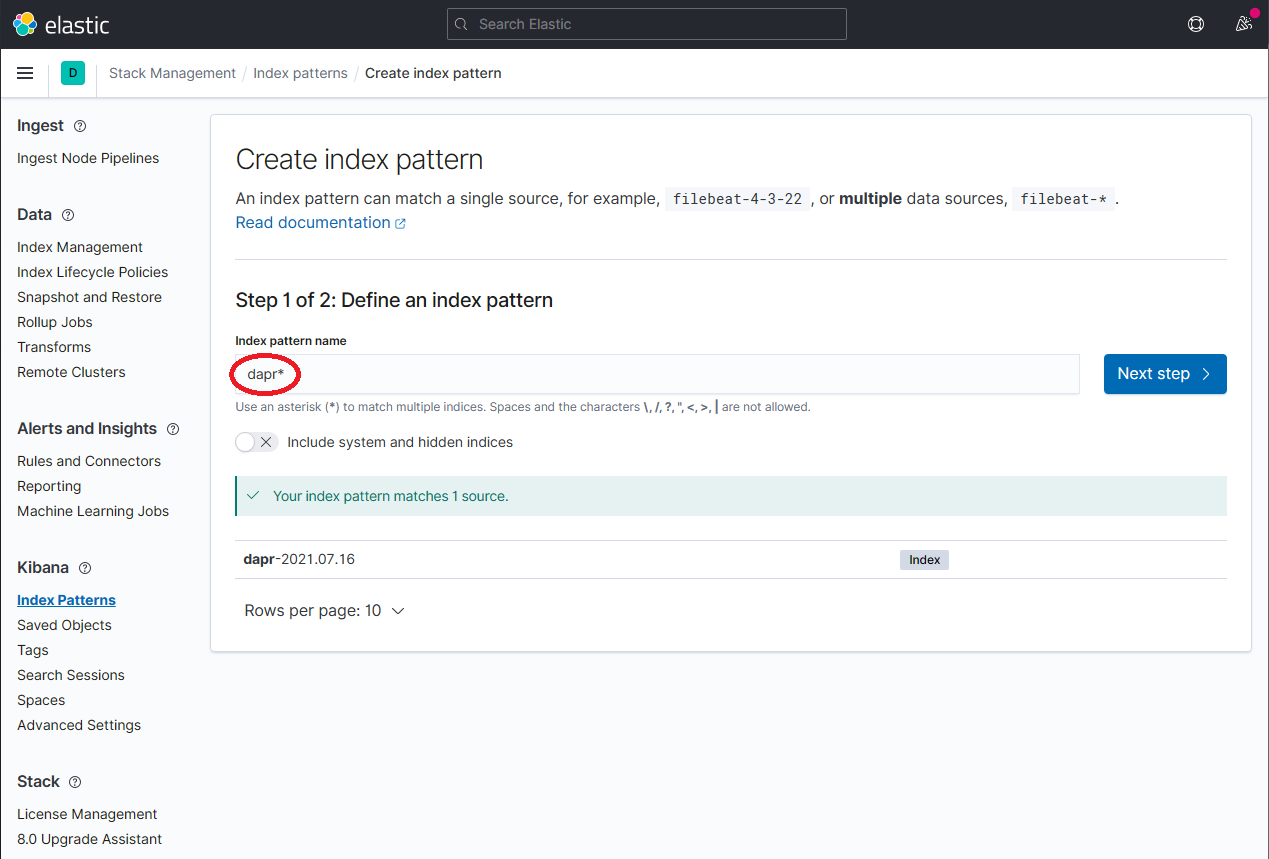
通过从 Time field 下拉列表中选择
@timestamp选项,配置与新索引模式一起使用的主时间字段。点击 Create index pattern 按钮完成索引模式的创建。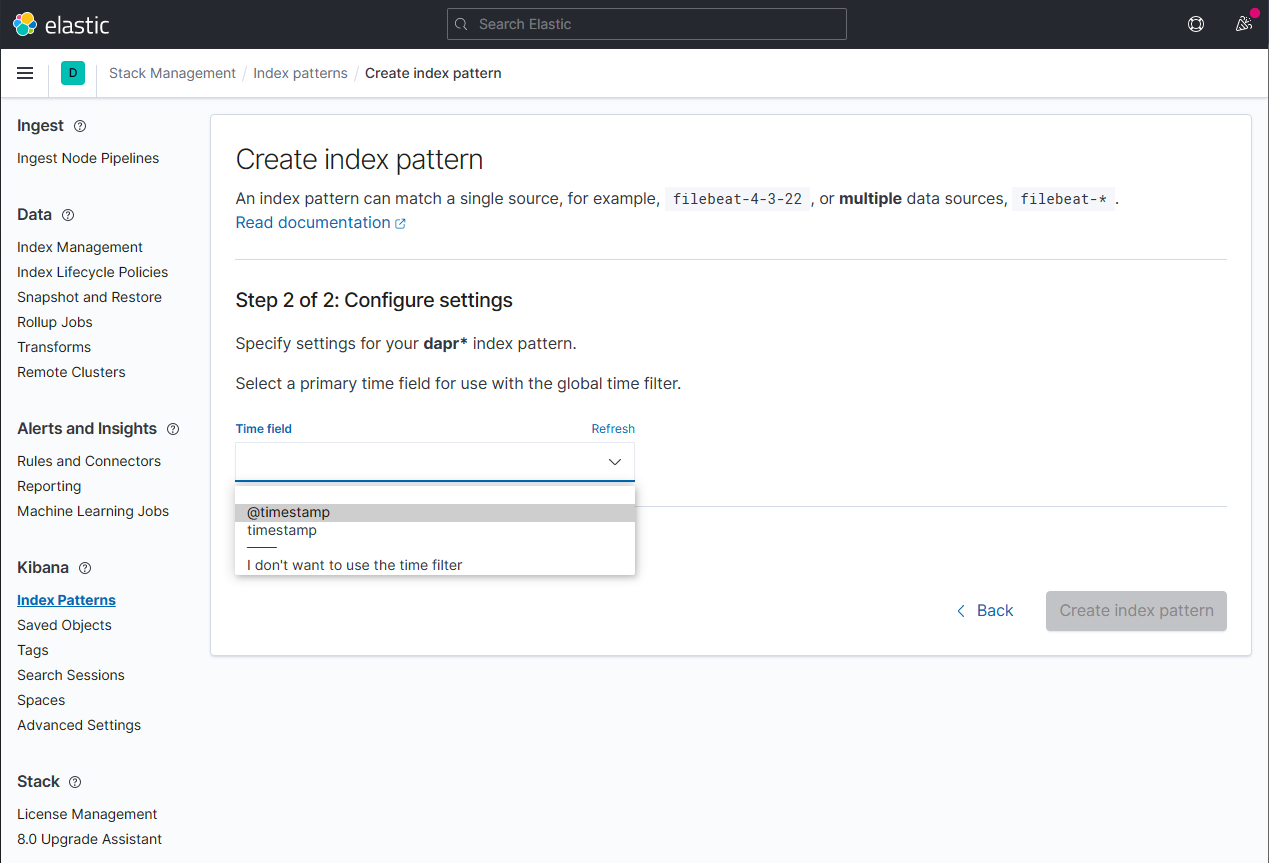
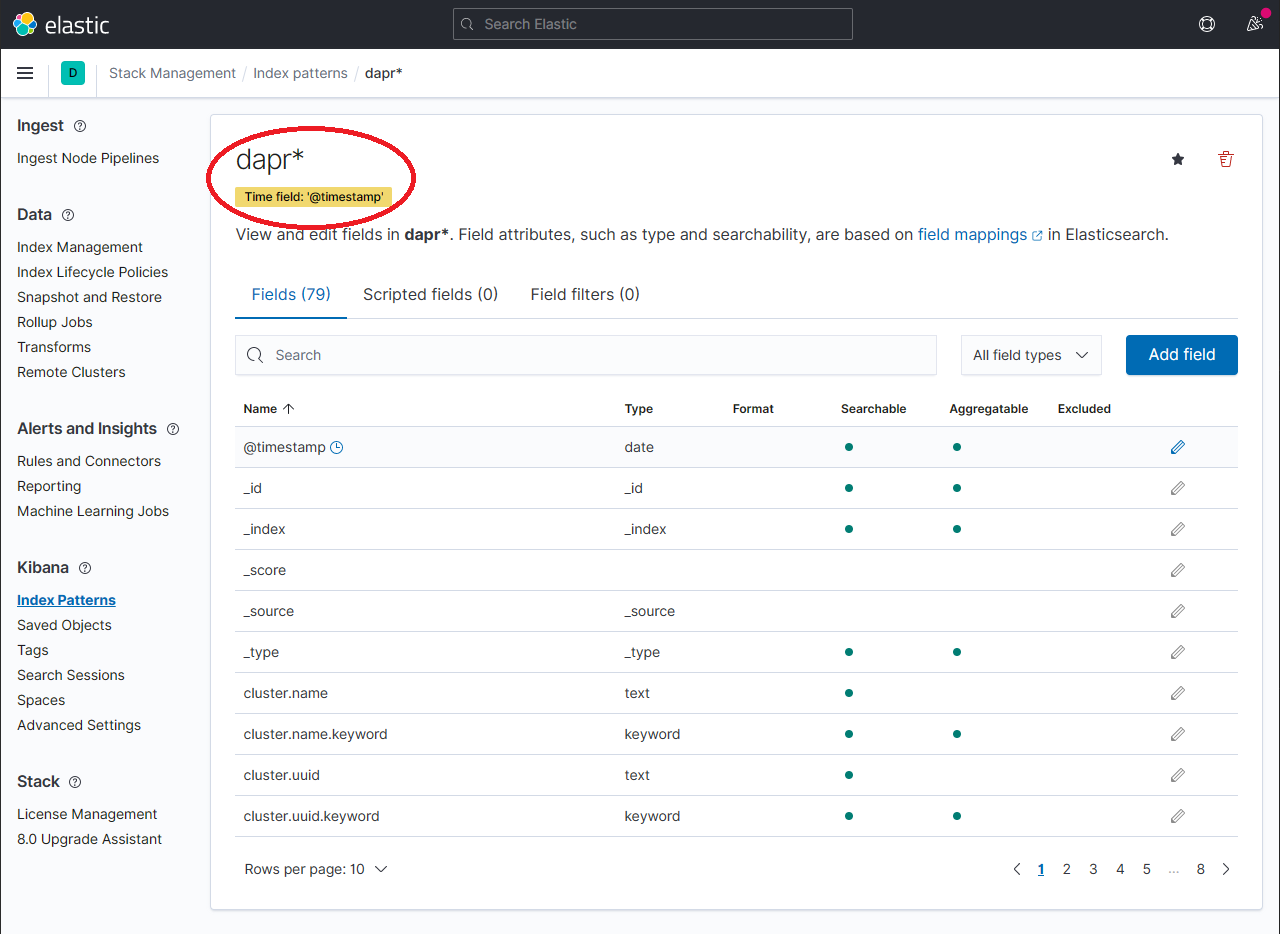
应该显示新创建的索引模式。通过使用 Fields 选项卡中的搜索框,确认感兴趣的字段(如
scope、type、app_id、level等)正在被索引。注意:如果你找不到索引字段,请稍候。搜索所有索引字段所需的时间取决于数据量和运行 Elasticsearch 的资源大小。
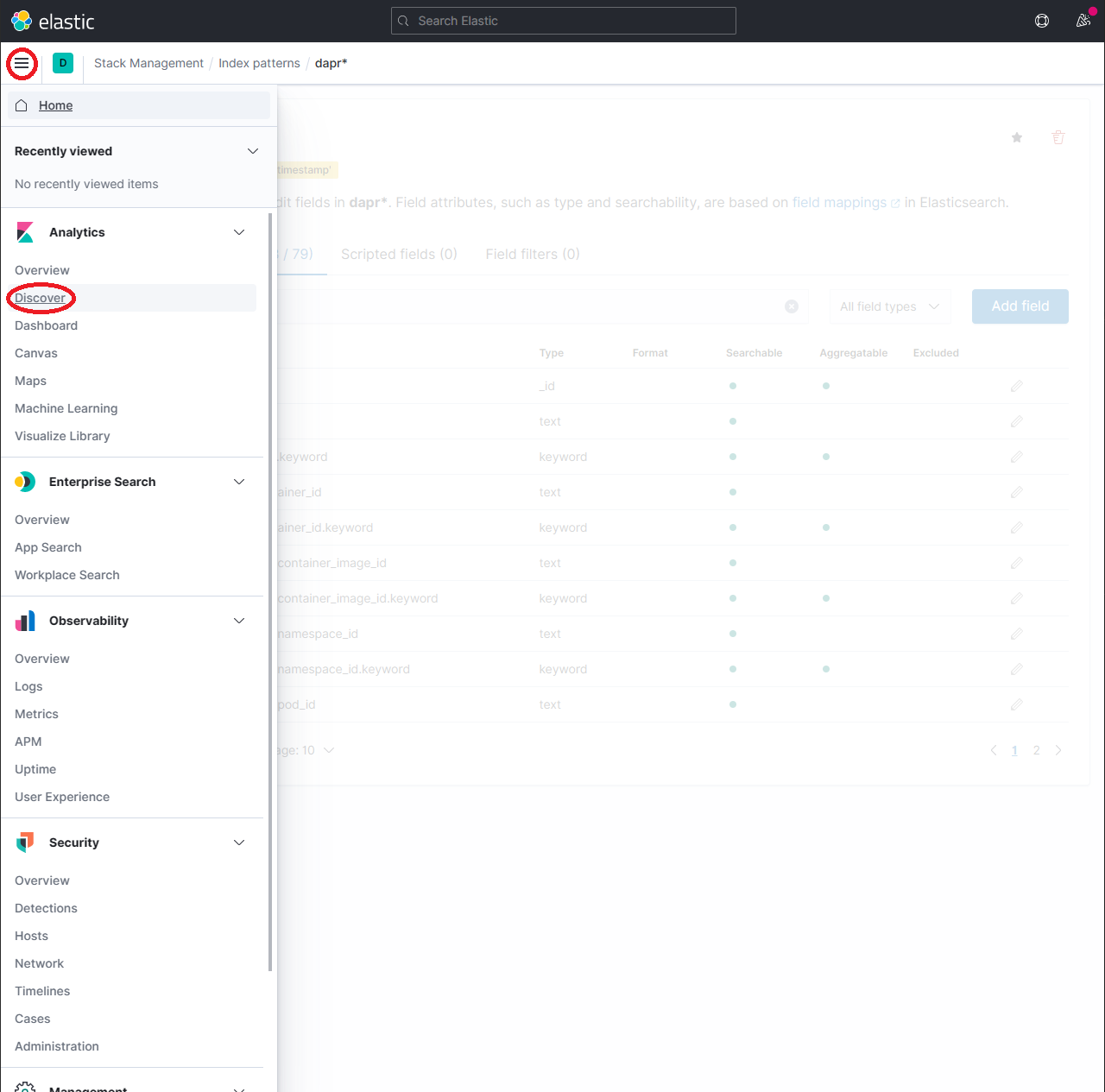
要浏览索引数据,展开下拉菜单并点击 Analytics → Discover。
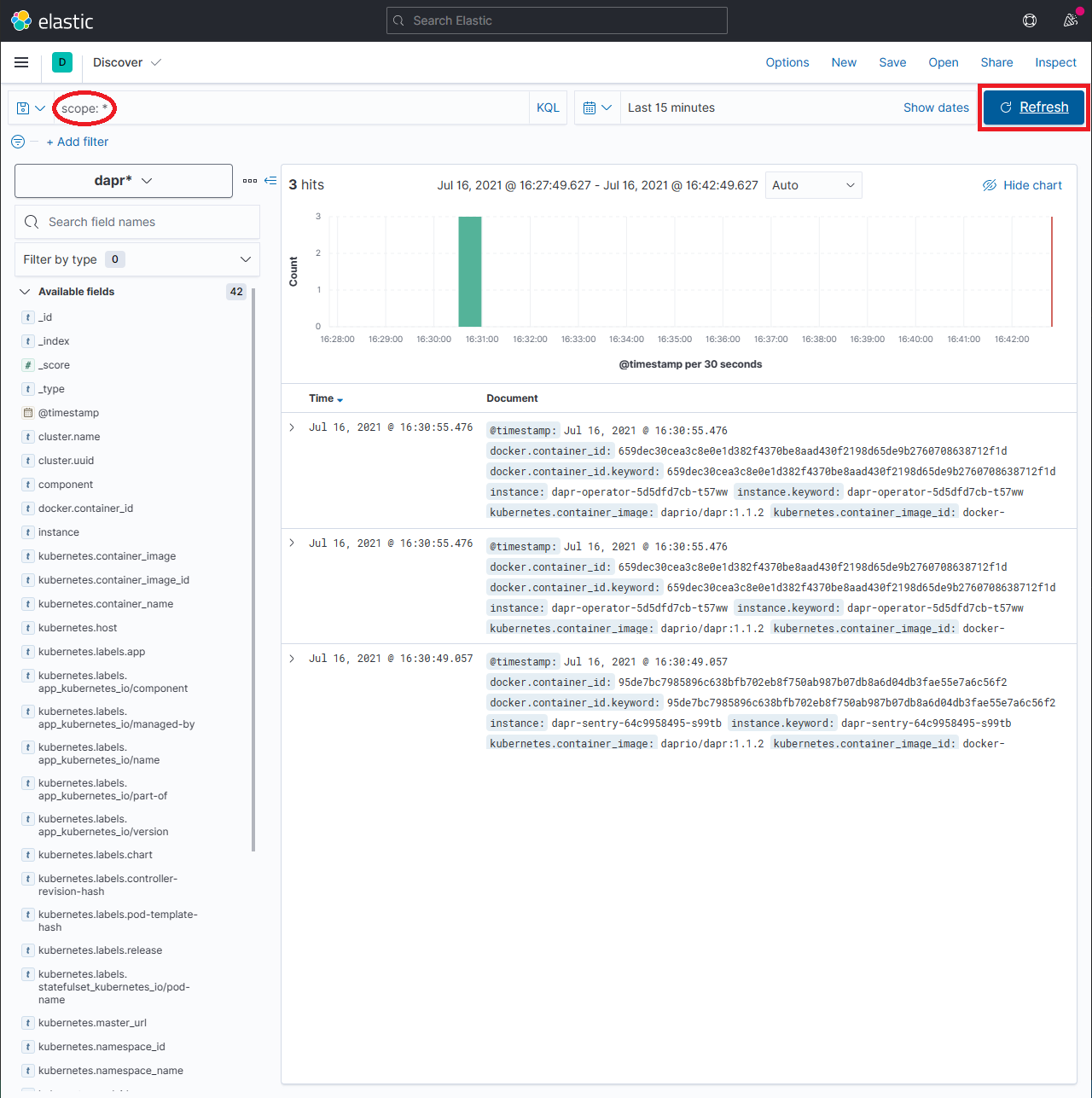
在搜索框中输入查询字符串,例如
scope:*,然后点击 Refresh 按钮查看结果。注意:这可能需要很长时间。返回所有结果所需的时间取决于数据量和运行 Elasticsearch 的资源大小。